WARNING: This is the _old_ Lustre wiki, and it is in the process of being retired. The information found here is all likely to be out of date. Please search the new wiki for more up to date information.
Architecture - Feature FS Replication: Difference between revisions
| Line 430: | Line 430: | ||
=== Space Balancing Migration === | === Space Balancing Migration === | ||
[[Image: | [[Image:700px-Space-balancing-migration.png]] | ||
=== Hadoop File System style Server Network Stripes === | === Hadoop File System style Server Network Stripes === | ||
Revision as of 11:34, 21 January 2010
Summary
This article describes a feature to facilitate efficient replication of large Lustre filesystems. Target filesystems may be Lustre or any other. This article does not address replication in the presence of clustered metadata.
Requirements
- The solution must scale to large file systems and will avoid full file system scans
- The algorithm must be exact - no modified files will be missed
- If the file system is static and the replication is performed the target will equal the source, barring errors arising during the synchronization
- The algorithms is safe when run repeatedly or run after an aborted attempt, will lead to understandable results when applied to a file system that is being modified during synchronization
- The solutions will use a list of modified files for synchronization
- The solution should have a suitable architecture to synchronize flash caches or object replicas
- The architecture of this solution will be suitable for (i) ldiskfs (ii) Lustre 1.8 (ldiskfs with MDS&OSS) (iii) Lustre 1.10 (new MDS with OSD based fids)
- The solution will address future changes of log record formats (since these will contain rollback & audit information also in due course)
- The solution may initially only work on file system without hard links (regular files with link count > 1).
- The synchronization mechanism has a facility to switch the role of source and target to perform failover and failback of services.
- The solution must be able to deal with different (future) record formats
- The solution must provide for reverse replication for the recovery case
Critical use cases
| identifier | attribute | summary |
| restart | availability | Metadata synchronization is aborted and restarted. The outcome needs to be correct. |
| file system full | correctness | Replication logs can cause the file system to be full. Correct messaging to user space is included in the solution. |
| MDT/OST log sync | correctness | OST records new file creation in log, but the event took place after the last MDT log sync |
| reverse replication | correctness | A master filesystem that is restarted after a failover to a backup filesystem must be made consistent with the backup |
restart
- Namespace changes may not be repeated (e.g. rm a, mv b a)
- Rename operations may be half-finished on target (e.g. rename, but haven't updated mtime of parent dir yet when power fails, so mtime is 'now' on target, but should be 'rename time' instead)
MDT/OST log sync
Correctly deal with the following cases: after a namespace log sync (epoch 1):
- New file is created
- Ignore OST updates to files that were created after the epoch. The creation will be noted in the next MDT epoch, at which point the entire file (data and md) must be copied.
- Sync namespace epoch 1
- (data record a) Modify file foo, ino=1
- (namespace record b) mv foo bar
- (namespace record c) Create file foo, ino=2
- (data record d) Modify file foo, ino=2
- Sync data
- (record a) lookup destname of ino=1: it is foo, so copy ino=1 to dest:/foo
- (record d) lookup destname of ino=2: when computing destname, we determine it did not exist at epoch 1 (we see create record in the active namespace log); return a special code and don't sync this file. Old "foo" on target is not modified.
- Sync namespace epoch 2
- (record b) move dest:/foo to dest:/bar
- (record c) create dest:/foo; copy ino=2 to dest:/foo
- File is deleted
- Leave the old version on dest alone. File will be deleted on dest in epoch 2; any recent data changes made on the source before the delete will be lost.
- See Solution Limitation A
- File moved off of OST (archive, space balance, ?)
- for file-level replication, this is a non-event
- for object-level replication, ?? leave special redirect record stub file
Reverse Replication
filesystem A is "failed over" to a backup system B that was current as of some epoch. When failing back, updates from B must be replicated on A such that A is consistent with B.
FIXME We need to decide something here Options: Changes on A after the epoch should be:
- reverted
- deleted files can be resurrected from B
- created files should be deleted
- namespace moves are undone
- ? files with mtimes after the epoch are recopied from B
- this assumes we have complete up-to-date changelogs
- kept, except in the case of conflicts
- conflict policy: new master always wins
- conflict policy: latest update wins
- conflict policy: ? something else
- changes since the epoch must be replicated back to B as well
Definitions
- Source File System
- The file system that is being changed and that we want to replicate.
- Target File System
- The file system that we wish to update to be identical to the source file system.
- Parent Tracker
- a subsystem responsible for recording the parent inode in disk file systems inodes, for pathname reconstruction.
- Changelog Generator
- a subsystem used by the MDS and OSS systems to generate changelog entries transactionally when the file system changes.
- Changelog Notifier
- subsystem responsible for notifying that a certain number of entries have been made, OR a certain amount of time has elapsed since changelog entries were made available, OR a large amount of changelog entries remains unprocessed.
- Changelog Consumer
- subsystem reading changelog entries for further processing.
- File Data & Attribute Synchronizer
- subsystem responsible for opening the correct source and target file and synchronizing the data/attributes in the file.
- Namespace Synchronizer
- subsystem responsible for synchronizing the namespace. This subsystem executes creation, deletion and rename operations.
- Layout Manager
- changes MDS object layout information associated with the replicated file data.
- Namespace Operation
- creation (open with create, mknod, symlink, mkdir, link), deletion (unlink, rmdir) or change (rename) of a name
- Replication Epoch
- A sequence of namespace operations, a set of inodes with attribute and file data changes, bracketed by an initial and final time and record number.
- Active log
- The changelog to which the filesystem is currently appending change records.
- Staged log
- One of zero or more 'closed' logs, no longer active.
Components


Parent Tracker
Uses relationships
- Used for
- current full path lookup given an inode or fid
- Requires
- the disk file system extended attribute interfaces to record primary parent inode. An indexed file to record pairs of inodes and secondary parents.
Logic
- When a new inode is created (creat, mknod, mkdir, open(O_CREAT), symlink, (link)), the parent directory inode number (inum) is automatically added as an EA. On Lustre, since OST inodes are precreated, we will modify the EA in filter_update_fidea. This means that an EA update is now required for these operations, which may change the transaction size by one block.
- Upon rename the parent inode is changed.
- The initial implementation may ignore multiple parents (hardlinks); for replication purposes synchronizing any one of the hardlinks is sufficient.
- modifications
- obdfilter (filter_update_fidea), ldiskfs (ldiskfs_new_inode)
Changelog Generator
Uses relationships
- Used for
- The disk file system on MDS or OSS to record changes in the file system.
- Requires
- llog or another transactional efficient logging mechanism to record changes, the file system or VFS api's to create logs
Exported Interfaces
- changelog accessor
Changelog Accessor
Changelogs are stored in a hidden directory at the filesystem root (/.changelog/). They are (mode 440 user "audit) files generated automatically by the filesystem when a special mount option is supplied (-o changelog). Only completed ("staged") log files are visible in the directory. Files are named with their changelog file sequence number. The current sequence number is stored on disk in a separate file (/.changelog/sequence).
- modifications
- ldiskfs; mdt/ost to allow serve special non-MDT-managed OST files to Lustre clients, mdt to serve special files directly to lustre clients without using OSTs
Interactions

Features and Limitations
- Log records are placed into a special changelog file.
- The records contain fids of existing objects and names of new objects
- The records contain the parent fid
- Changelog records are recorded within the filesystem transaction
- Modified files are noted in the changelog log only once (not at every transaction)
- Every instance of a namespace change operation (rename, create, delete) is recorded in the log
Theorem: Given a changelog with the properties described above a correct synchronization can be performed. Proof:
Logic
- Global changelog_active_start_time is set to the active changelog's crtime at startup and every time a new active changelog is created.
- When an inode is first read from disk (or created), save the old mtime, so we can easily detect when it changes
- Every time an inode is dirtied, check old_mtime.
- If old_mtime is after changelog_active_start_time, then inode has already been added to changelog; don't add it again.
- If old_mtime is earlier, then add the change record to the active changelog
- Update old_mtime to current mtime. If mtime is not later than changelog_active_start_time, we can use ctime, dtime, or current time instead of mtime; it just needs to be a time after changelog_active_start_time.
- Record every namespace change operation in the log for path reconstruction of a live filesystem. Record every instance, not just once per log. To simplify the log format, move/rename operations may be broken up into two log records (the first with the old name/parent, the second with the new).
- Include full path information in these records
- modifications
- ldiskfs (ldiskfs_mark_inode_dirty, ldiskfs_new_inode, ldiskfs_link, ldiskfs_unlink, ldiskfs_rmdir, ldiskfs_rename, ldiskfs_ioctl, ldiskfs_truncate, ldiskfs_xattr_set, ldiskfs_setattr)
Pathname Lookup
Uses relationships
- Used for
- Data Replicator
- Requires
- Parent Tracker, Changelog Accessor, ability to temporarily lock filesystem against namespace changes
Exported Interfaces
- source_path(ino, *sourcepath, *end_rec)
- ino : inode or fid from data changelog record
- sourcepath : current path on source, as of end_rec
- end_rec : latest namespace record number
- may return ENOENT: file has been deleted from source
- target_path(sourcepath, end_rec, namespace_log, *targetpath)
- namespace_log : the name of the namespace log that we have last synced on the target
- targetpath : the path for this inode on the target system, as of the end of namespace_log
- may return ENOENT: file does not exist (yet) on target
Features and Limitations
- Lives on MDT, exported interface to Lustre clients
Logic
source_path
- lock filesystem against renames
- lookup current full path name on MDT from ino/fid
- open inode. Return ENOENT if doesn't exist
- open parent ino's as stored in EA
- likely that path elements will not be cached on the MDT during this lookup
- return full path in sourcepath
- return last record number in the active namespace changelog in end_rec
- unlock filesystem against renames
target_path
- generate a list of parent path elements from sourcepath (names or inodes)
- search backward through the namespace logs (active and staged) from end_rec, replacing any renamed path elements with their old (previous) version, until either:
- we reach the first record after end of the given namespace_log
- a create record for this inode is encountered; return ENOENT
- return targetpath
- Hardlinks
- source_path() will always return a single path. The path need not be consistent. target_path() will always return a single valid path on the target to one of the hardlinks (renames along this "chosen" path will be undone.) Renames along any other hardlinked paths may be ignored: target_path is used to update file data and attributes, which are shared between all the hardlinked files on the target. The renames of the other hardlinked paths themselves are synchronized by the Namespace Synchronizer.
Changelog Notifier
Uses relationships
- Used for
- The disk file system, to notify the Changelog Consumer of available data
- Requires
- Changelog Generator
Exported Interfaces
- notification of new or excessive changelog
- updates sequence file
Features and Limitations
- When an active changelog has reached a preset limit of size, record count, or active time, the notifier:
- increases the sequence number (changelog identifier)
- creates a new active changelog with the new identifier
- marks the old changelog as staged (unhidden).
- A Changelog Consumer could poll the sequence file for mtime changes, signalling a new staged file.
Logic
Multiple logs are kept on each disk file system volume; zero or more non-active ("finished") logs and exactly 1 active log. Finished logs will be stored in a special directory (i.e. /.changelog). Staged logs are named with a monotonically increasing sequence number. The sequence number of the latest staged log is stored on disk in a separate file (/.changelog/sequence).
- Begin recording into the active log. We append to this file until some trigger criteria is met (either time or log size). The active log is not visible to filesystem users.
- When the trigger criteria is met
- stop writing into the active log
- create a new active log
- thenceforth record all subsequent changes into the new active log
- indicate that the old log is now staged by marking it as visible and updating the sequence file
- When a user process has finished processing the files referred to in the staged log (including synchronizing the files remotely), it signals its completion by deleting the staged log (which may act as part of a new trigger criteria.)
- The cycle begins again from step 2.
- If the number of staged logs exceeds some threshold, the Notifier records a warning in the syslog (D_WARNING)
A user process is signaled that a new changelog is ready by polling the sequence file mtime.
If the user process dies, upon restart it re-reads the staged log, perhaps repeating old actions (sync). If the server dies, upon restart it continues recording into the active log.
- modifications
- ldiskfs
Changelog Consumer

Uses relationships
- Used for
- Managing filesystem replication
- Requires
- Namespace Synchronizer, File Data & Attribute Synchronizer, Changelog Notifier
Exported Interfaces
- replicate(lustre_root_path, target_root_path, [implicit target sync file])
- lustre_root_path : path to root of Lustre source fs
- target_root_path : path to root of target (must be locally mounted!)
The last namespace log record processed is stored in a sync file on the target. This file is read at the beginning of replicate() to determine the next start record.
Features and Limitations
The consumer uses the changelogs to coordinate filesystem replication using the Namespace Synchronizer and the File Data Synchronizer described below.
- Multiple replica filesystems may exist at different sync points.
Logic
A synchronization cycle consists of synchronizing the namespace and file data for each changed file/dir. Special care is needed because a file/dir may be renamed at any time during the synchronization cycle, changing the path name resolution.
Synchronization for Lustre requires both OST and MDT logs, with path lookup on the MDT for any files changed on the OSTs.
- Synchronize the namespace change operations from a staged log using the Namespace Synchronizer (MDT)
- Now destination namespace mirrors source, but file contents/md may not match
- For all other ops (md and data) in the staged log(s on the MDT and all OSTs), call the Data/MD Synchronizer
- Data/MD synchronization should be carried out in parallel for each OST and the MDT.
- Now destination filesystem namespace matches, but data/md may be newer than a theoretical snapshot of the source taken at Namespace Sync time.
- modifications
- new userspace utility
File Data & Attribute Synchronizer
Uses relationships
- Used for
- Changelog Consumer - data replication
- Requires
- Changelog Accessor, Path Lookup, VFS api to open file by ino/fid, remote filesystem access
Features and Limitations
- Multiple data change logs exist and these can be synchronized in parallel.
- Individual changes are NOT recorded; only the fact that an inode is dirty. The data and metadata of the file on the target filesystem will match the source at the time of the copy, not as of the namespace sync. In other words, the target is not an exact snapshot of the source filesystem at a single point.
- Open-by-fid requires root privileges
Logic
- Find pathnames in the destination
- Data records are recorded with inode/fids on the source. To transform this into an operation that can be applied to the destination file system we find the target file name using:
- read data record
- source_path(ino, *sourcepath, *end_rec)
- if ENOENT: file has been deleted from source; don't synchronize
- target_path(sourcepath, end_rec, namespace_change_log, *targetpath)
- if ENOENT: file does not exist (yet) on target; don't synchronize
- Synchronize file data and attributes
- iopen(ino) on source for reading
- requires root privileges on the source
- open(targetpath) on target for writing
- copy file data and attributes from source to target
- may require temporary access permission changes on the target
- ownership changes may require root privileges on the target
- data copy may be predicated on mtime change, checksum, etc. May use rsync as a primitive here.
- data changes should be made before attribute changes (mtime), in case of power failure
- Parallel file processing
- if multiple OSTs (and/or the MDT) all note that a file needs to be synced, they may race. Normal locking should insure no inconsistent results, but copying the same file multiple times should be avoided for efficiency. Simple rules like "don't copy if target mtime is later than source mtime" will help, but the open(target)'s may still race after such checks. Possible solutions include using a lockfile on the target (difficult to determine if lockfile is still valid after a crash bec. possible distributed lockers), or interprocess communications on the sources, or perhaps a special "sync_in_progress" bit on the MDT inode set in the open-by-fid path. FIXME nonfatal, performance
- modifications
- new userspace component (data syncer), ldiskfs/mdt (ioctl open by inode)
Namespace Synchronizer
Uses relationships
- Used for
- Changelog Consumer - namespace replicator
- Requires
- Changelog Accessor, remote filesystem access
Logic
- Path lookup at namespace change time
- Records are recorded with inode/fids and full path (up to the filesystem root) on the source at the time of the change. At this point the path is likely to be cached so this should be cheap. The old (mvFrom) and the new (mvTo) paths are recorded
- Implementing a record
- The metadata synchronizer processes all namespace change records in the changelog such that target filesystem namespace matches the source namespace as of the close of this changelog, including the mtime of the affected directories.
- Finding the first valid record to implement
- The synchronizer performs an ordered write on the target filesystem. This records the record number (transno) of the namespace record that it is currently working on in a special file on the target, as well as a full copy of the transaction record, before it makes the namespace changes to the target. This leads to a re-do operation that is understandable:
- a deletion is repeated if the name is still there. The mtime is updated if the name is not there and the mtime does not match the post-mtime in the record.
- a creation is repeated if the name is not yet there.
- a rename is repeated if the names or parent mtimes are not what they should be.
- the full transaction record on the replica is used for recovery in case of master-to-replica failover.
- modifications
- new userspace utility
Solution Limitations
Notable limitations to the proposed solution:
A. A replicated file system is not a snapshot taken at a single point in time on a live filesystem. It is a namespace snapshot, combined with data and metadata contents that may be later than the snapshot time. In the case of deleted files, we may miss some data/md updates.
B. Data and attribute synchronization may require temporary access permission changes on the target.
C. Open-by-inode may require root permission on source
D. A new record is not created for every data/md change; at most one per file per epoch is recorded. (However, every namespace change is recorded). This may have implications for potential audit, undo future features.
States and Transitions
Source File System
- A directory for changelog files (per MDT/OST)
- Staged and active changelogs
- header: start record, start mtime
- records: transno, ino, parent ino, mtime (see Changelog Format above)
- footer: final record, final mtime, (future) ZFS snapshot name associated with the final state
- Sequence file
- active changelog filename
Changelog Format
Changelogs are packed binary data files. The first record is a header; subsequent records use the following structure:
- magic (_u32)
- flags (_u32)
- record_num (__u64) (transno)
- record_type(_u16)
- ino(long)
- parent_ino(long)
- namespace changes only:
- old mtime (struct timespec)
- note: post-op mtime is in the next namespace change rec, or current mtime
- strlen(_u16)
- pathname(string)
- note: for renames, "from" is in the mvFrom rec, "to" is in the mvTo rec
- old mtime (struct timespec)
- record_types
- Create, Link, Unlink, Rmdir, mvFrom, mvTo, Ioctl, Trunc, Xattr, Setattr, *unknown
The header record:
- magic (_u32)
- flags (_u32)
- start_record_num (__u64)
- changelog_file_seqno(long)
- log start time (struct timespec)
- strlen(_u16)
- note(string)
Tail record:
- magic (_u32)
- flags (_u32)
- end_record_num (__u64)
- next_changelog_seqno(long)
- log end time (struct timespec)
- strlen(_u16)
- snapshot name(string) (future)
Target file system
- Last attempted namespace record (entire record)
- Last attempted data / metadata records for each replicator
- optional, allows for faster recovery
- OST index
- replication start
- replication last completed
State Changes in the Source File System
- Some file system transactions result in changelog records recorded in the active changelog
- file data or metadata modifications in files that have not already been added to the active changelog
- any namespace change operations
- Active changelogs are occasionally staged. Multiple staged logs may exist.
- The sequence file is updated to reflect the latest staged log.
- "Completed" changelogs may be deleted at will (after synchronization)
File:Source state.png (image missing in original Arch wiki article)
{kind=link}
State Changes in the Target File System
- Each time a namespace operation is attempted the last attempted record is recorded. This may also be done for attribute and file synchronization operations, for efficient restarts (note that this would require a separate file per replication 'chunk').
- Namespace operations are recorded on the target filesystem using user-level filesystem commands (mv, rm, mknod, touch) or the posix file API (open, creat, unlink, ioctl) to adjust file, directory, and parent directory names and metadata.
- Data / metadata operations are recorded on the target filesystem using user-level filesystem commands (cp, rsync, touch) or the posix file API (read, write, ioctl) to synchronize file content and metadata
Related Applications
The mechanisms to use a list containing fids of modified files for synchronization hinges on opening files by fid or correctly computing the pathname on a previously synced replica. This mechanism has applications elsewhere in Lustre which we discuss here.
Flash Cache Sync demo
Media:700px-Flash-cache-sync-demo.png
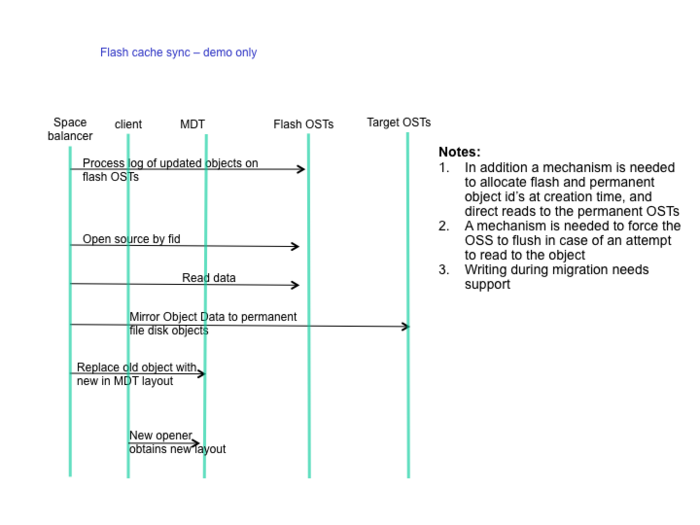{kind=link}
Fast Incremental Backup

Space Balancing Migration

Hadoop File System style Server Network Stripes
{kind=link}
Alternatives
mtime on MDT
A always-current mtime on the MDT allows us to record changed files on the MDT only (no OST logging). Bug 11063 has an update-mtime-on-close patch, but this is unsafe in case of client crash. We could use full SOM-style recovery to guarantee mtime (backport from HEAD), but this may be very complicated given MDT changes. Arguably the changelog we are creating on the OSS nodes is similar to the recovery mechanisms used by SOM.
NOTE: on HEAD (with SOM), we need only record file (metadata) changes on the MDT, since every OST change will result in an updated mtime on the MDT inode. This eliminates the logging requirement for replication on the OSTs, removing possible racing OST syncs. The synchronizer on the MDT would be responsible for distributing chunks of the data synchronization to multiple clients and insuring their completion.
ZFS snapshots
By taking a snapshot on the MDT at the end of each epoch, the target pathname reconstruction step can be avoided. "Current" pathname of the inode is looked up on the snapshot; this gives the target pathname directly.
Potentially, if cluster-wide synchronized snapshots were available, then true snapshot backups could be made.
References
to be removed: HLD reqs
Entry Criteria
You need to have on hand
1. Architecture document 2. Quality Attribute Scenarios & Use cases 3. LOGT, LOGD
1. External Functional specifications
Following the architecture, define prototypes for all externally
visible interfaces (library functions, methods etc) of all
modules changed by the program. Be sufficiently detailed in the
specification to cover:
a. Layering of API's
b. How memory for variables / parameters is allocated
c. In what context the functions run
2. High level logic
Use high level pseudocode to indicate how all elements of the
program will be implemented.
3. Use case scenarios
a. Write use cases for all normal and abnormal uses of externally
visible functions.
b. Write use cases demonstrating interoperability between the
software with and without this module
c. Write use cases demonstrating the scalability use cases
mentioned in the architecture.
d. Include use case scenarios for all locking situations and
describe how likely they are.
4. State machine design
With great care describe state machines included, used or affected by the module. Describe the transitions between states. Be alert to the fact that any function called by the module can change a state machine in the environment and this may interact with state machines in your model.
Pay particular attention to:
a. locking (ordering, lock/unlock)
b. cache usage
c. recovery (connect, disconnect, export/import/request state
machines)
d. disk state changes
5. High Level Logic Design
a What synchronization primitives (lock types etc) need to be chosen
to handle locking use cases most efficiently.
6. Test plan
Give a high level design of all tests and describe test cases to cover/verify all critical use cases and quality attribute scenarios
7. Plan review
Review the estimates in the TSP cycle plan based on the information obtained during the work on the HLD. Bring wrong estimates to the attention of the planning manager in the weekly meeting.
8. EXIT CRITERIA
A well formed design with prototypes, state machines, use cases, logic.